What Is a Transformer Model?
对 What Is a Transformer Model? | NVIDIA Blogs 这篇文章的翻译。
A transformer model is a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence.
Transformer模型是一个神经网络,通过跟踪顺序数据中的关系(例如这个句子中的单词)来学习上下文和意义。
If you want to ride the next big wave in AI, grab a transformer.
如果你想要跟随人工智能的下一个重大浪潮,选择一款Transformer模型吧。
They’re not the shape-shifting toy robots on TV or the trash-can-sized tubs on telephone poles.
它们并不是电视上变形的玩具机器人,也不是电话杆上垃圾桶大小的容器。
那么,什么是Transformer模型呢?
A transformer model is a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence.
Transformer模型是一种神经网络,通过跟踪顺序数据(例如这个句子中的单词)中的关系来学习上下文和因此意义。
Transformer models apply an evolving set of mathematical techniques, called Attention or self-attention, to detect subtle ways even distant data elements in a series influence and depend on each other.
Transformer模型应用一组不断发展的数学技术,称为注意力或自注意力,来检测序列中即使是远距离的数据元素之间的微妙影响和依赖关系。
First described in a 2017 paper from Google, transformers are among the newest and one of the most powerful classes of models invented to date. They’re driving a wave of advances in machine learning some have dubbed transformer AI.
Transformer模型最早在谷歌的一篇2017年的论文中进行了描述,它们是迄今为止最新且最强大的模型类别之一。它们推动了机器学习领域的一波进步,有些人称之为Transformer AI。
Stanford researchers called transformers “foundation models” in an August 2021 paper because they see them driving a paradigm shift in AI. The “sheer scale and scope of foundation models over the last few years have stretched our imagination of what is possible,” they wrote.
斯坦福大学的研究人员在2021年8月的一篇论文中将Transformer模型称为“基础模型”,因为他们认为它们正在推动人工智能领域的范式转变。他们写道:“过去几年基础模型的规模和范围之大已经超出了我们对可能性的想象力。”
Transformer模型能做什么?
Transformers are translating text and speech in near real-time, opening meetings and classrooms to diverse and hearing-impaired attendees.
Transformer模型能够几乎实时地翻译文本和语音,使得会议和课堂对于多样化和听力受损的参与者变得更加开放。
They’re helping researchers understand the chains of genes in DNA and amino acids in proteins in ways that can speed drug design.
它们正在帮助研究人员以能够加速药物设计的方式理解DNA中基因链和蛋白质中的氨基酸链。
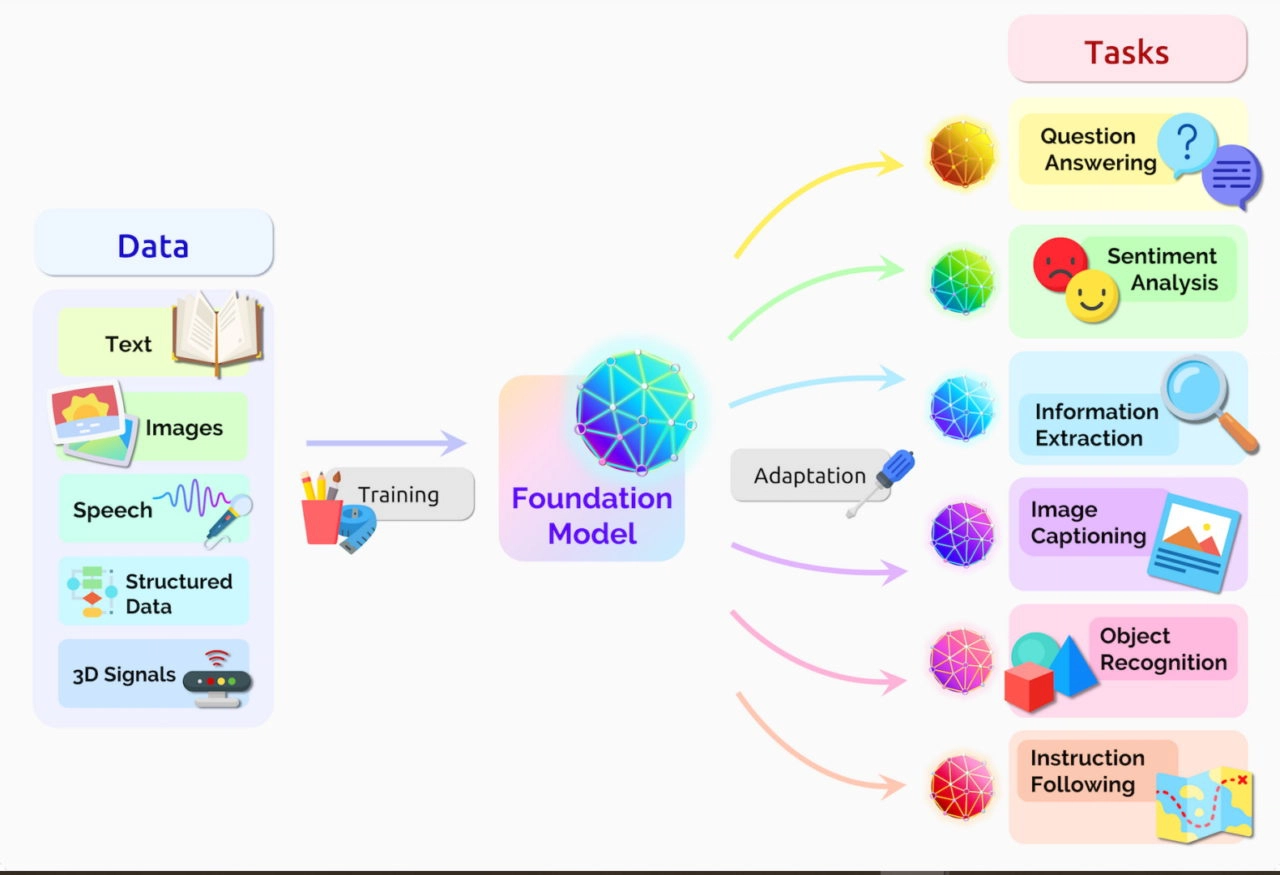
Transformers, sometimes called foundation models, are already being used with many data sources for a host of applications.
Transformer模型,有时被称为基础模型,已经被用于许多数据源的各种应用中。
Transformers can detect trends and anomalies to prevent fraud, streamline manufacturing, make online recommendations or improve healthcare.
Transformer模型可以检测趋势和异常,以防止欺诈、优化制造过程、进行在线推荐或改进医疗保健。
People use transformers every time they search on Google or Microsoft Bing.
每当人们在Google或微软必应上进行搜索时,都在使用Transformer模型。
Transformer AI的良性循环
Any application using sequential text, image or video data is a candidate for transformer models.
任何使用顺序文本、图像或视频数据的应用都是Transformer模型的候选对象。
That enables these models to ride a virtuous cycle in transformer AI. Created with large datasets, transformers make accurate predictions that drive their wider use, generating more data that can be used to create even better models.
这使得这些模型能够在Transformer AI中形成良性循环。通过使用大规模数据集创建,Transformer模型能够进行准确的预测,推动其更广泛的应用,从而生成更多的数据,这些数据可以用来创建更好的模型。
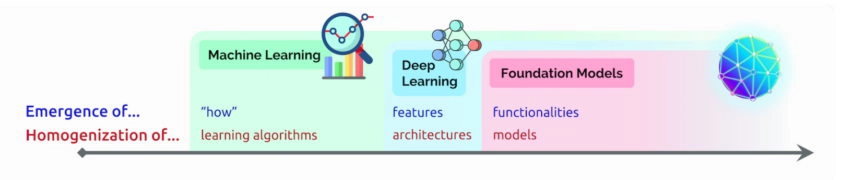
Stanford researchers say transformers mark the next stage of AI’s development, what some call the era of transformer AI.
斯坦福大学的研究人员表示,Transformer标志着人工智能发展的下一个阶段,有些人称之为Transformer AI时代。
“Transformers made self-supervised learning possible, and AI jumped to warp speed,” said NVIDIA founder and CEO Jensen Huang in his keynote address this week at GTC.
“Transformer模型使得自监督学习成为可能,从而让人工智能迅速发展,”NVIDIA创始人兼首席执行官Jensen Huang在本周的GTC主题演讲中表示。
Transformer模型取代了CNN和RNN模型
Transformers are in many cases replacing convolutional and recurrent neural networks (CNNs and RNNs), the most popular types of deep learning models just five years ago.
在许多情况下,Transformer模型正在取代卷积神经网络(CNN)和循环神经网络(RNN),这两者是五年前最流行的深度学习模型类型。
Indeed, 70 percent of arXiv papers on AI posted in the last two years mention transformers. That’s a radical shift from a 2017 IEEE study that reported RNNs and CNNs were the most popular models for pattern recognition.
事实上,过去两年发布在arXiv上的人工智能论文中,有70%提到了Transformer模型。这与2017年IEEE的一项研究完全不同,该研究报告称RNN和CNN是最受欢迎的模式识别模型。
无标签,更高性能
Before transformers arrived, users had to train neural networks with large, labeled datasets that were costly and time-consuming to produce. By finding patterns between elements mathematically, transformers eliminate that need, making available the trillions of images and petabytes of text data on the web and in corporate databases.
在Transformer出现之前,用户需要使用大规模标记的数据集对神经网络进行训练,而这种数据集的制作成本高昂且耗时。通过数学上找到元素之间的模式,Transformer消除了这种需求,使得互联网上的数万亿张图片和数PB的文本数据以及企业数据库中的数据得以利用。
In addition, the math that transformers use lends itself to parallel processing, so these models can run fast.
此外,Transformer模型使用的数学方法适合并行处理,因此这些模型可以运行得非常快速。
Transformers now dominate popular performance leaderboards like SuperGLUE, a benchmark developed in 2019 for language-processing systems.
Transformer模型现在主导着像SuperGLUE这样的流行性能排行榜,SuperGLUE是一个于2019年开发的用于语言处理系统的基准测试。
Transformer模型如何进行注意力机制?
Like most neural networks, transformer models are basically large encoder/decoder blocks that process data.
和大多数神经网络一样,Transformer模型基本上是由处理数据的大型编码器/解码器块组成。
Small but strategic additions to these blocks (shown in the diagram below) make transformers uniquely powerful.
对这些块进行小而战略性的添加(如下图所示),使得Transformer模型具有独特的强大能力。
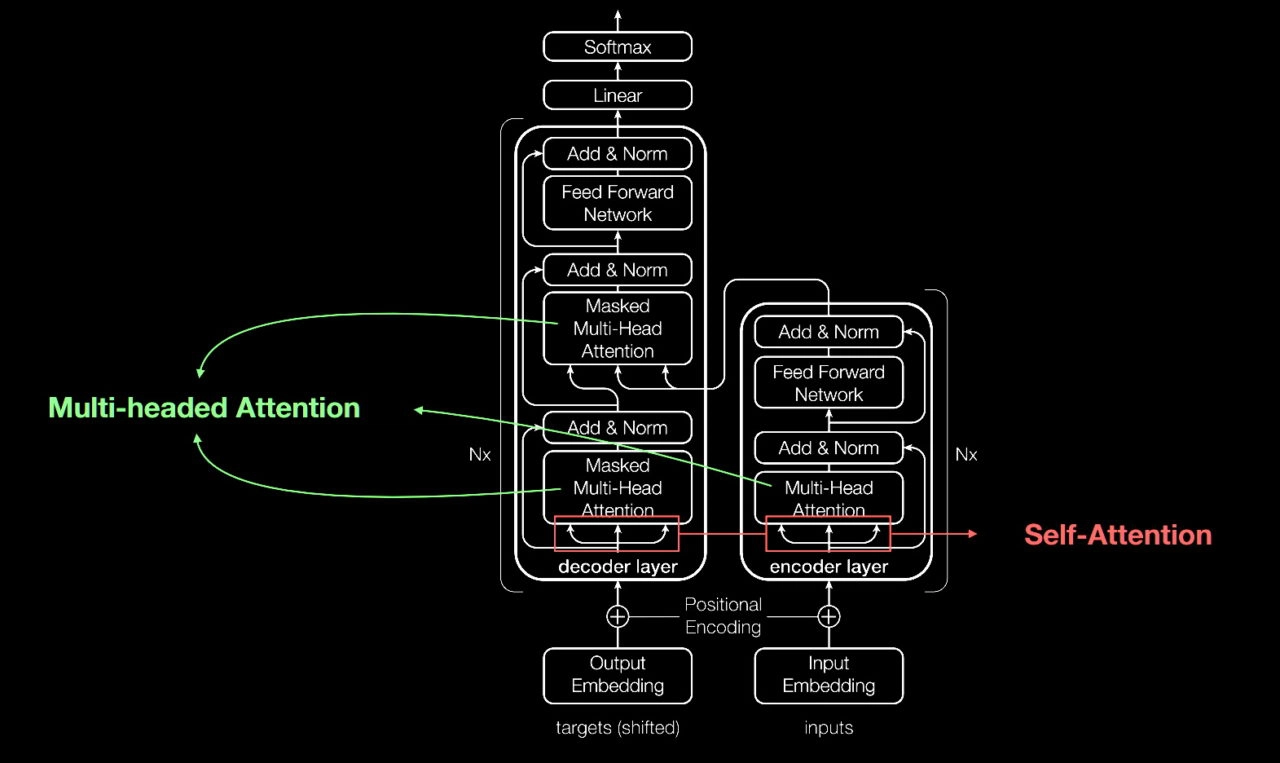
A look under the hood from a presentation by Aidan Gomez, one of eight co-authors of the 2017 paper that defined transformers.
从Aidan Gomez的演示中可以看到一些细节,他是2017年定义Transformer的论文的八位合著者之一。
Transformers use positional encoders to tag data elements coming in and out of the network. Attention units follow these tags, calculating a kind of algebraic map of how each element relates to the others.
Transformer模型使用位置编码器来标记进出网络的数据元素。注意力机制会按照这些标记,计算每个元素与其他元素之间关系的一种代数映射。
Attention queries are typically executed in parallel by calculating a matrix of equations in what’s called multi-headed attention.
通常通过在所谓的多头自注意力机制中计算一组方程的矩阵来并行执行注意力查询。
With these tools, computers can see the same patterns humans see.
借助这些工具,计算机可以看到与人类相同的模式。
自注意力机制找到了意义
For example, in the sentence:
例如,在这个句子中:
She poured water from the pitcher to the cup until it was full.
她从水罐倒水到杯子里,一直倒到满为止。
We know “it” refers to the cup, while in the sentence:
我们知道 "it" 指的是杯子,而在下面的句子中:
She poured water from the pitcher to the cup until it was empty.
她从水罐倒水到杯子里,一直倒到它变空。
We know “it” refers to the pitcher.
我们知道 "it" 指的是水罐。
“Meaning is a result of relationships between things, and self-attention is a general way of learning relationships,” said Ashish Vaswani, a former senior staff research scientist at Google Brain who led work on the seminal 2017 paper.
“意义是事物之间关系的结果,而自注意力是一种学习关系的通用方法,”谷歌Brain团队的前高级研究科学家Ashish Vaswani在领导了这篇具有开创性的2017年论文的工作时说道。
“Machine translation was a good vehicle to validate self-attention because you needed short- and long-distance relationships among words,” said Vaswani.
“机器翻译是验证自注意力的一个很好的工具,因为你需要在单词之间建立短距离和长距离的关系,”Vaswani说道。
“Now we see self-attention is a powerful, flexible tool for learning,” he added.
“现在我们看到自注意力是一种强大、灵活的学习工具,”他补充道。
Transformer是如何得名的?
Attention is so key to transformers the Google researchers almost used the term as the name for their 2017 model. Almost.
注意力在Transformer中非常重要,以至于谷歌的研究人员几乎将其作为他们2017年模型的名称。几乎是这样。
“Attention Net didn’t sound very exciting,” said Vaswani, who started working with neural nets in 2011.
“Attention Net听起来并不令人兴奋,”Vaswani说道,他从2011年开始研究神经网络。
Jakob Uszkoreit, a senior software engineer on the team, came up with the name Transformer.
Jakob Uszkoreit,团队中的高级软件工程师,提出了Transformer这个名字。
“I argued we were transforming representations, but that was just playing semantics,” Vaswani said.
“我争辩说我们正在转换表示,但那只是在玩词语游戏,”Vaswani说道。
Transformer的诞生
In the paper for the 2017 NeurIPS conference, the Google team described their transformer and the accuracy records it set for machine translation.
在2017年的NeurIPS会议论文中,谷歌团队描述了他们的Transformer模型以及它在机器翻译方面所创造的准确性记录。
Thanks to a basket of techniques, they trained their model in just 3.5 days on eight NVIDIA GPUs, a small fraction of the time and cost of training prior models. They trained it on datasets with up to a billion pairs of words.
多亏了一系列技术手段,他们在仅仅3.5天的时间内,利用八块NVIDIA GPU对模型进行了训练,这只是以往模型训练所需时间和成本的一小部分。他们使用了高达数十亿个单词对的数据集进行训练。
“It was an intense three-month sprint to the paper submission date,” recalled Aidan Gomez, a Google intern in 2017 who contributed to the work.
“在提交论文的截止日期之前的三个月时间里,我们进行了紧张的冲刺,”回忆起这项工作的谷歌实习生Aidan Gomez说道,他在2017年参与了这项工作。
“The night we were submitting, Ashish and I pulled an all-nighter at Google,” he said. “I caught a couple hours sleep in one of the small conference rooms, and I woke up just in time for the submission when someone coming in early to work opened the door and hit my head.”
“我们提交论文的那天晚上,Ashish和我在谷歌彻夜未眠,”他说道。“我在其中一个小会议室里睡了几个小时,当有人早早来上班打开门撞到我的头时,我恰好醒来准备提交论文。”
It was a wakeup call in more ways than one.
这不仅仅是一种方式上的提醒,也是在其他方面的一种警示。
“Ashish told me that night he was convinced this was going to be a huge deal, something game changing. I wasn’t convinced, I thought it would be a modest gain on a benchmark, but it turned out he was very right,” said Gomez, now CEO of startup Cohere that’s providing a language processing service based on transformers.
“那天晚上,Ashish告诉我他相信这将会是一件重大的事情,一种改变游戏规则的东西。我并不相信,我认为它只会在基准测试上有一些适度的进展,但事实证明他是非常正确的,”现在担任初创公司Cohere的首席执行官的Gomez说道,该公司提供基于Transformer的语言处理服务。
机器学习的一个重要时刻
Vaswani recalls the excitement of seeing the results surpass similar work published by a Facebook team using CNNs.
Vaswani回忆起当时看到结果超过Facebook团队使用CNN进行的类似工作时的兴奋。
“I could see this would likely be an important moment in machine learning,” he said.
他说:“我可以看到这很可能是机器学习领域的一个重要时刻。”
A year later, another Google team tried processing text sequences both forward and backward with a transformer. That helped capture more relationships among words, improving the model’s ability to understand the meaning of a sentence.
一年后,另一个谷歌团队尝试使用Transformer模型对文本序列进行正向和反向处理。这有助于捕捉单词之间更多的关系,提高模型理解句子意义的能力。
Their Bidirectional Encoder Representations from Transformers (BERT) model set 11 new records and became part of the algorithm behind Google search.
他们的双向编码器表示来自Transformer(BERT)模型刷新了11项新纪录,并成为了Google搜索算法的一部分。
Within weeks, researchers around the world were adapting BERT for use cases across many languages and industries “because text is one of the most common data types companies have,” said Anders Arpteg, a 20-year veteran of machine learning research.
在几周内,全球的研究人员开始将BERT适应于许多语言和行业的应用案例中,"因为文本是公司最常见的数据类型之一,"机器学习研究的20年资深专家Anders Arpteg说道。
将Transformer投入实际应用
Soon transformer models were being adapted for science and healthcare.
很快,Transformer模型开始被应用于科学和医疗领域。
DeepMind, in London, advanced the understanding of proteins, the building blocks of life, using a transformer called AlphaFold2, described in a recent Nature article. It processed amino acid chains like text strings to set a new watermark for describing how proteins fold, work that could speed drug discovery.
伦敦的DeepMind利用一种名为AlphaFold2的Transformer模型,进一步推进了对蛋白质的理解,蛋白质是生命的基本构建单元。AlphaFold2将氨基酸链处理成类似文本字符串的形式,创造性地描述了蛋白质折叠的过程,这项工作有助于加快药物发现的进程,并在最近的《自然》文章中进行了描述。
AstraZeneca and NVIDIA developed MegaMolBART, a transformer tailored for drug discovery. It’s a version of the pharmaceutical company’s MolBART transformer, trained on a large, unlabeled database of chemical compounds using the NVIDIA Megatron framework for building large-scale transformer models.
阿斯利康(AstraZeneca)和Nvidia共同开发了MegaMolBART,这是一种专为药物发现定制的Transformer模型。它是制药公司的MolBART Transformer的一个版本,使用NVIDIA Megatron框架在一个大型的无标签化学化合物数据库上进行训练,用于构建大规模Transformer模型。
阅读分子,医疗记录
“Just as AI language models can learn the relationships between words in a sentence, our aim is that neural networks trained on molecular structure data will be able to learn the relationships between atoms in real-world molecules,” said Ola Engkvist, head of molecular AI, discovery sciences and R&D at AstraZeneca, when the work was announced last year.
“就像AI语言模型可以学习句子中单词之间的关系一样,我们的目标是让神经网络能够在分子结构数据上学习现实世界分子中原子之间的关系,”阿斯利康的分子AI、发现科学与研发部门负责人Ola Engkvist在去年宣布该项目时表示。
Separately, the University of Florida’s academic health center collaborated with NVIDIA researchers to create GatorTron. The transformer model aims to extract insights from massive volumes of clinical data to accelerate medical research.
另外,佛罗里达大学的学术卫生中心与NVIDIA的研究人员合作开发了GatorTron。这个Transformer模型旨在从大规模的临床数据中提取洞见,加快医学研究的进展。
Transformer模型的应用范围不断扩大
Along the way, researchers found larger transformers performed better.
在这个过程中,研究人员发现更大的Transformer模型表现更好。
For example, researchers from the Rostlab at the Technical University of Munich, which helped pioneer work at the intersection of AI and biology, used natural-language processing to understand proteins. In 18 months, they graduated from using RNNs with 90 million parameters to transformer models with 567 million parameters.
例如,慕尼黑工业大学的Rostlab研究团队在AI和生物学交叉领域开创性工作方面做出了贡献,他们使用自然语言处理来理解蛋白质。在18个月内,他们从使用具有9000万参数的RNN模型逐步过渡到具有5.67亿参数的Transformer模型。
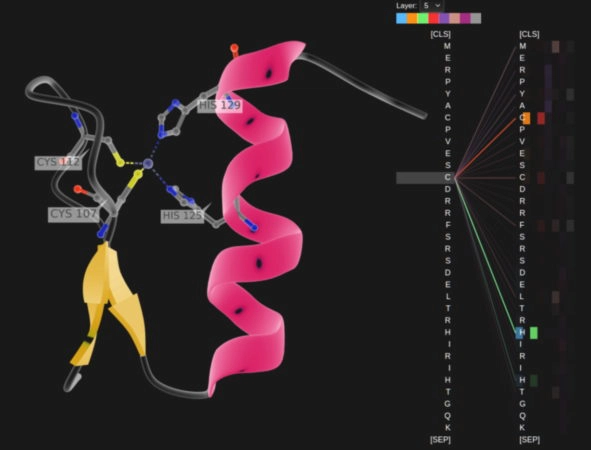
Rostlab researchers show language models trained without labeled samples picking up the signal of a protein sequence.
Rostlab的研究人员展示了在没有标记样本的情况下,语言模型能够捕捉到蛋白质序列的信号。
The OpenAI lab showed bigger is better with its Generative Pretrained Transformer (GPT). The latest version, GPT-3, has 175 billion parameters, up from 1.5 billion for GPT-2.
OpenAI实验室通过其Generative Pre-trained Transformer(GPT)展示了“越大越好”的观点。最新版本000.wiki/GPT-3拥有1750亿个参数,相比之下,GPT-2只有15亿个参数。
With the extra heft, GPT-3 can respond to a user’s query even on tasks it was not specifically trained to handle. It’s already being used by companies including Cisco, IBM and Salesforce.
凭借更强大的能力,GPT-3可以回应用户的查询,即使在它没有专门训练处理的任务上也能做到。它已经被包括思科、IBM和Salesforce在内的公司所使用。
一个巨型Transformer的故事
NVIDIA and Microsoft hit a high watermark in November, announcing the Megatron-Turing Natural Language Generation model (MT-NLG) with 530 billion parameters. It debuted along with a new framework, NVIDIA NeMo Megatron, that aims to let any business create its own billion- or trillion-parameter transformers to power custom chatbots, personal assistants and other AI applications that understand language.
在11月份,NVIDIA和Microsoft创造了一个新的里程碑,宣布推出了拥有5300亿个参数的Megatron-Turing自然语言生成模型(MT-NLG)。与此同时,它还搭配了一个新的框架,即NVIDIA NeMo Megatron,旨在使任何企业能够创建自己的十亿或万亿参数的Transformer模型,以驱动定制的聊天机器人、个人助理和其他能够理解语言的人工智能应用。
MT-NLG had its public debut as the brain for TJ, the Toy Jensen avatar that gave part of the keynote at NVIDIA’s November 2021 GTC.
MT-NLG在NVIDIA 2021年11月的GTC(GPU Technology Conference)上作为TJ的大脑进行了首次公开亮相。TJ是一个Toy Jensen虚拟形象,它在演讲中扮演了重要角色。
“When we saw TJ answer questions — the power of our work demonstrated by our CEO — that was exciting,” said Mostofa Patwary, who led the NVIDIA team that trained the model.
“当我们看到TJ回答问题时,我们的工作展示了强大的力量,这让人兴奋不已,”带领训练这个模型的NVIDIA团队的负责人Mostofa Patwary表示。
Creating such models is not for the faint of heart. MT-NLG was trained using hundreds of billions of data elements, a process that required thousands of GPUs running for weeks.
创建这样的模型并非易事。MT-NLG是通过使用数千亿个数据元素进行训练的,这个过程需要数千个GPU持续运行数周。
“Training large transformer models is expensive and time-consuming, so if you’re not successful the first or second time, projects might be canceled,” said Patwary.
"训练大型Transformer模型是昂贵且耗时的,所以如果第一次或第二次尝试没有成功,项目可能会被取消,"Patwary表示。

“Megatron helps me answer all those tough questions Jensen throws at me,” TJ said at GTC 2022.
"TJ在2022年的GTC上说:“Megatron帮助我回答了Jensen提出的所有难题。”
万亿参数的Transformer模型
Today, many AI engineers are working on trillion-parameter transformers and applications for them.
如今,许多人工智能工程师正在研究万亿参数的Transformer模型以及相关应用。
“We’re constantly exploring how these big models can deliver better applications. We also investigate in what aspects they fail, so we can build even better and bigger ones,” Patwary said.
Patwary说道:“我们不断探索这些大型模型如何提供更好的应用。我们也研究它们的失败方面,这样我们就可以构建更好、更大的模型。”
To provide the computing muscle those models need, our latest accelerator — the NVIDIA H100 Tensor Core GPU — packs a Transformer Engine and supports a new FP8 format. That speeds training while preserving accuracy.
为了提供这些模型所需的计算能力,我们最新的加速器——NVIDIA H100 Tensor Core GPU——搭载了Transformer引擎,并支持新的FP8格式。这可以在保持准确性的同时加快训练速度。
With those and other advances, “transformer model training can be reduced from weeks to days” said Huang at GTC.
借助这些和其他的进展,黄仁勋在GTC上表示:“Transformer模型的训练时间可以从几周缩短到几天。”
对于Transformer模型而言,MoE(Mixture of Experts)意味着更多的可能性。
Last year, Google researchers described the Switch Transformer, one of the first trillion-parameter models. It uses AI sparsity, a complex Mixture of Experts (MoE) architecture and other advances to drive performance gains in language processing and up to 7x increases in pre-training speed.
去年,谷歌的研究人员描述了Switch Transformer,这是其中一个首个拥有万亿参数的模型。它利用了AI稀疏性、复杂的混合专家(MoE)架构和其他先进技术,提高了语言处理的性能,并且在预训练速度上提升了多达7倍。
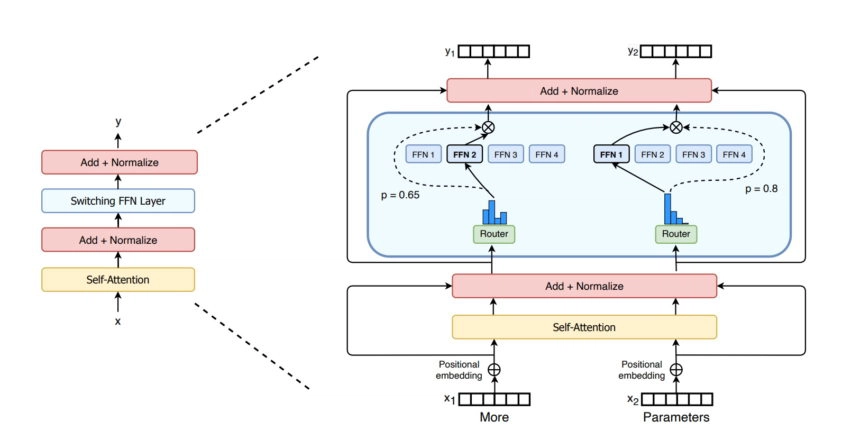
The encoder for the Switch Transformer, the first model to have up to a trillion parameters.
Switch Transformer的编码器,这是第一个拥有高达万亿参数的模型。
For its part, Microsoft Azure worked with NVIDIA to implement an MoE transformer for its Translator service.
在这方面,微软Azure与NVIDIA合作,为其Translator服务实现了一个MoE Transformer。
应对Transformer模型的挑战
Now some researchers aim to develop simpler transformers with fewer parameters that deliver performance similar to the largest models.
现在,一些研究人员的目标是开发简化的Transformer模型,其参数数量较少,但能够提供与最大模型类似的性能。
“I see promise in retrieval-based models that I’m super excited about because they could bend the curve,” said Gomez, of Cohere, noting the Retro model from DeepMind as an example.
Cohere的Gomez表示:“我对检索式模型抱有很大的期望,因为它们可以改变现状,”他提到了DeepMind的Retro模型作为一个例子。
Retrieval-based models learn by submitting queries to a database. “It’s cool because you can be choosy about what you put in that knowledge base,” he said.
检索式模型通过向数据库提交查询来进行学习。他说:“这很酷,因为你可以选择性地将什么放入知识库中。”

在追求更高性能的竞争中,Transformer模型变得越来越庞大。
The ultimate goal is to “make these models learn like humans do from context in the real world with very little data,” said Vaswani, now co-founder of a stealth AI startup.
现在的一个隐秘人工智能初创公司的联合创始人Vaswani表示,最终的目标是“使这些模型像人类一样从现实世界的上下文中学习,而只需要很少的数据”。
He imagines future models that do more computation upfront so they need less data and sport better ways users can give them feedback.
他想象未来的模型将在前期进行更多的计算,这样它们就需要更少的数据,并且具备更好的用户反馈方式。
“Our goal is to build models that will help people in their everyday lives,” he said of his new venture.
在谈到他的新创业项目时,他表示:“我们的目标是构建能够帮助人们改善日常生活的模型。”
安全、负责任的模型
Other researchers are studying ways to eliminate bias or toxicity if models amplify wrong or harmful language. For example, Stanford created the Center for Research on Foundation Models to explore these issues.
其他研究人员正在研究如何消除模型放大错误或有害语言时的偏见或毒性。例如,斯坦福大学创建了“基础模型研究中心”来探索这些问题。
“These are important problems that need to be solved for safe deployment of models,” said Shrimai Prabhumoye, a research scientist at NVIDIA who’s among many across the industry working in the area.
“这些是需要解决的重要问题,以确保模型的安全部署,”NVIDIA的研究科学家Shrimai Prabhumoye说道,他是业界众多从事这一领域研究的人员之一。
“Today, most models look for certain words or phrases, but in real life these issues may come out subtly, so we have to consider the whole context,” added Prabhumoye.
Prabhumoye补充道:“如今,大多数模型会寻找特定的单词或短语,但在现实生活中,这些问题可能会以微妙的方式呈现,因此我们必须考虑整个上下文。”
“That’s a primary concern for Cohere, too,” said Gomez. “No one is going to use these models if they hurt people, so it’s table stakes to make the safest and most responsible models.”
Gomez表示:“这也是Cohere的主要关注点。如果这些模型对人们造成伤害,没有人会使用它们,所以我们要确保建立最安全、最负责任的模型。”
超越视野
Vaswani imagines a future where self-learning, attention-powered transformers approach the holy grail of AI.
Vaswani想象着一个未来,自我学习、由注意力驱动的Transformer模型将接近人工智能的圣杯。
“We have a chance of achieving some of the goals people talked about when they coined the term ‘general artificial intelligence’ and I find that north star very inspiring,” he said.
他说:“我们有机会实现人们在提出‘通用人工智能’这个术语时谈论的一些目标,而我发现这个指引非常鼓舞人心。”
“We are in a time where simple methods like neural networks are giving us an explosion of new capabilities.”
“我们正处在一个简单方法(如神经网络)带来新能力爆炸的时代。”
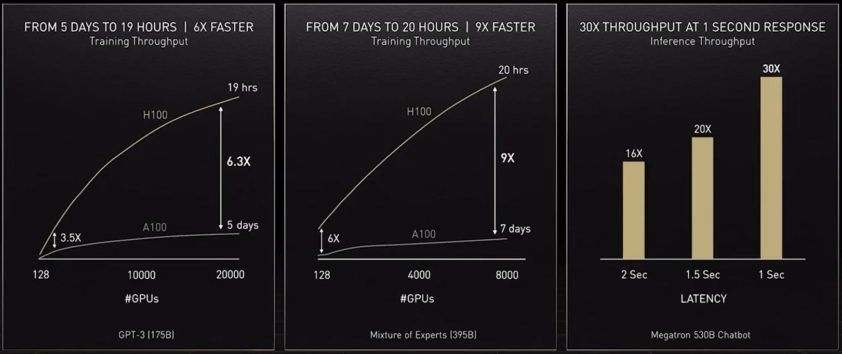
Transformer training and inference will get significantly accelerated with the NVIDIA H100 GPU.
通过NVIDIA H100 GPU,Transformer模型的训练和推理将大大加速。
Learn more about transformers on the NVIDIA Technical Blog.
请在NVIDIA技术博客上了解更多关于Transformer的内容。
本文作者:Maeiee
本文链接:What Is a Transformer Model?
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
